[NLP] CS224N - [1] Word Vectors: Word2Vec

CS224N Series
- [1] Word Vectors: Word2Vec
- [2] Word Vectors: GloVe
- [3] Word Senses and Neural Networks
- [4] Backprop and Neural Networks
- [5] Syntactic Structure and Dependency Parsing
- [6] Recurrent Neural Networks (RNNs)
- [7] LSTM RNNs
- [8] Seq2Seq, Attention
- [9] Self-Attention and Transformers
본 포스팅은 CS224N 1강을 정리한 글로, 단어의 의미를 표현하는 Word Vector와 대표적인 Word2Vec 모델에 대해 설명한다.
WordNet
단어의 의미를 표현하는 가장 초기의 방법 중 하나인 WordNet은 단어 간의 관계를 명시적으로 제공한다.
WordNet은 단어 간 유사도, 동의어 관계 Synonym Sets, 상위-하위 관계 Hypernyms 를 구조적으로 정의한 사전이다.
WordNet Structure
Synonym Sets (Synsets): 동의어 집합- good $\approx$ beneficial $\approx$ adventageous
Hypernyms: “is a” 관계- panda $\subset$ mammal $\subset$ animal
Code
1
2
3
4
5
6
from nltk.corpus import wordnet as wn
# "good" 단어의 동의어 집합 확인
synsets = wn.synsets("good")
for s in synsets:
print(s)
하지만, WordNet은 몇 가지 문제점을 안고 있다.
- 세부 의미 부족: 단어의 문맥을 제대로 반영하지 못함
good과beneficial은 미묘하게 다른 의미를 갖지만, 항상 동일시함
- 새로운 단어 부족: 새로 등장하는 단어를 빠르게 반영하지 못함
wicked,badass,bombest등의 새로운 단어를 상시 추가해야 하는데 번거로움
- 주관적: 사전에 추가할 때 주관이 반영됨
- 수동 구축: 인간의 노력이 필요하므로 확장이 어려움
One-hot Vector
WordNet의 문제를 극복하기 위해 컴퓨터가 단어를 더 효율적으로 다루기 위해 단어를 벡터로 표현하는 시도들이 등장하였다.
단어를 벡터로 표현하는 가장 기본적인 방법인 One-hot Vector는 각 단어를 고유한 인덱스로 표현한다.
벡터 공간에서 하나의 차원만 1로 활성화되며, 나머지는 모두 0으로 채워진다.
이렇게 벡터 또는 행렬의 대부분의 값이 0으로 표현되는 방법을 희소 표현 Sparse Representation이라고 부른다.
 One-hot Vector
One-hot Vector
One-hot Vector는 단어를 단순히 고유 인덱스로 표현하므로, 단어의 수는 곧 벡터의 차원 수가 되어 차원이 기하급수적으로 증가한다.
또한, motel과 hotel처럼 의미적으로 비슷한 단어도 벡터 공간에서는 orthogonal하여 유사도를 측정할 수 없다.
이 문제를 해결하기 위해, 단어의 문맥을 활용하여 의미를 나타내는 새로운 접근법이 필요하다.
Distributional Semantics
Distributional Semantics는 단어의 의미를 문맥에서 찾는 접근법으로, 함께 사용되는 단어를 통해 특정 단어의 의미를 알 수 있다는 아이디어에 기반한다.
“You shall know a word by the company it keeps.” - J.R. Firth 1957
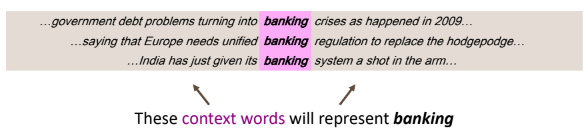 특정 단어의 의미를 결정하는 주변 단어
특정 단어의 의미를 결정하는 주변 단어
특정 단어 $w$의 의미는 고정된 길이 window-size 내의 단어들의 집합에 의해 결정된다.
Word Vectors
하지만, Distribution Semantics는 여전히 단어 문맥 정보를 수작업으로 처리하거나, 단순 통계에 의존한다.
더욱 정교한 표현을 위해 단어를 실수 벡터로 표현하는 방법이 등장하게 된다.
Word Vectors는 단어를 고차원 실수 벡터로 표현하여 단어 간 의미적 유사도를 수치적으로 표현할 수 있다.
의미적으로 유사한 단어들은 벡터 공간에서 가깝게 위치하도록 학습된다.
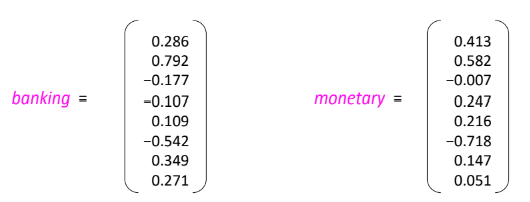 유사 단어에 대한 가까운 벡터 표현
유사 단어에 대한 가까운 벡터 표현
Word Vector는 다음의 특징을 가진다.
- Dense Representation: 대부분의 값이 0이 아닌 밀집 벡터이다.
- Similarity Measurement: 벡터 간 내적 또는 코사인 방법을 통해 유사도를 계산할 수 있다.
| One-hot Vector | Word Vector | |
|---|---|---|
| 차원 | 고차원 (단어 수) | 저차원 |
| 표현 | 희소 벡터 (Sparse) | 밀집 벡터 (Dense) |
| 표현 방법 | 수동 | 훈련 데이터로부터 학습 |
| 값의 타입 | 0 or 1 | 실수 |
Word2Vec
Word2Vec는 단어 벡터를 학습하는 대표적인 방법으로, 단어의 의미적 유사성을 벡터 공간에 잘 반영하도록 학습된다. 1
Overview
Word2Vec은 두 가지 학습 방식을 제공한다.
Skip-gram: 중심 단어로 주변 단어 예측CBOW (Continuous Bag of Words): 주변 단어들로 중심 단어 예측
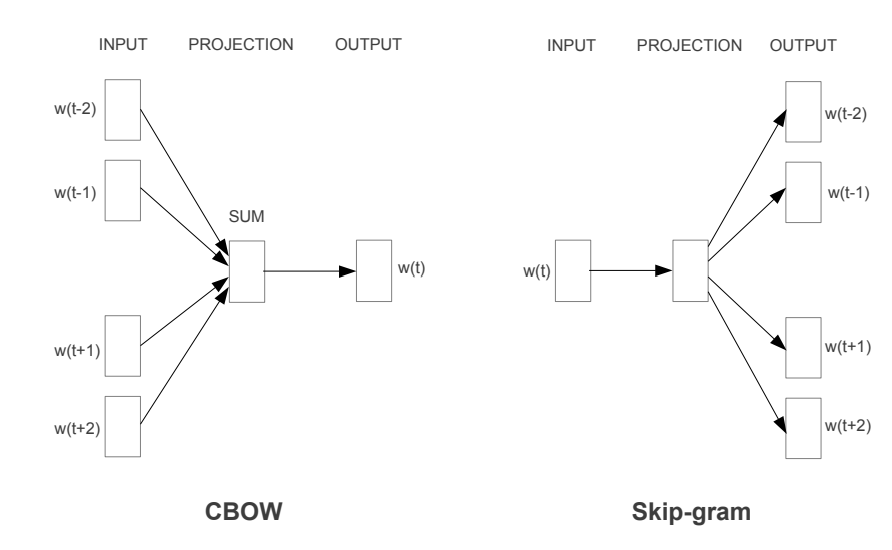 CBOW & Skip-gram
CBOW & Skip-gram
본 포스팅은 Skip-gram을 기준으로 설명하며, 목표는 중심 단어 $c$를 기준으로 주변 단어 $o$를 예측하는 조건부 확률 $(P(o \mid c))$를 학습하는 것이다.
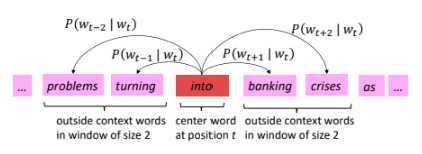 중심 단어를 활용한 주변 단어 확률 계산
중심 단어를 활용한 주변 단어 확률 계산
Objective Function
주어진 데이터 $D$가 $T$개의 단어로 이루어져 있고, 각 중심 단어 $w_t$에 대해 윈도우 크기 $m$만큼의 주변 단어를 고려했을 때,
전체 우도 Likelihood 는 모든 중심 단어와 그 주변 단어들의 조건부 확률을 곱한 값이다.
- $w_t$: 시점 $t$의 중심 단어
- $w_{t+j}$: 중심 단어 주변에 있는 $j$번째 단어
- $\theta$: 학습할 모든 파라미터 (단어 벡터 $u, v$)
Word2Vec은 미분이 용이하기 위해 로그 우도 Log Likelihood 를 최대화하는 문제로 변환한다.
\[\log L(\theta) = \sum_{t=1}^T \sum_{-m \leq j \leq m, j \neq 0} \log P(w_{t+j} \mid w_t; \theta)\]로그 우도의 부호를 반전시켜 목적 함수 Objective Function 를 최소화하는 문제로 변환한다.
\[J(\theta) = -\frac{1}{T} \log L(\theta) = -\frac{1}{T} \sum_{t=1}^T \sum_{-m \leq j \leq m, j \neq 0} \log P(w_{t+j} \mid w_t; \theta)\]목적 함수를 최소화하기 위해, 조건부 확률 $P(w_{t+j} \mid w_t; \theta)$을 계산해야 한다.
소프트맥스 함수를 통해 다음과 같이 계산할 수 있다.
\[P(o \mid c) = \frac{\exp(u_o^\top v_c)}{\sum_{w \in V} \exp(u_w^\top v_c)}.\]- 유사도 계산: 중심 단어 $c$의 벡터 $v_c$와 주변 단어 $o$의 벡터 $u_o$ 간의 내적 $(u_o^\top v_c)$
- 지수 함수 적용: 양수로 만들기 위해 내적 값을 지수화
- 정규화: 전체 단어 집합 $V$에 대해 확률 분포를 만들기 위해 정규화
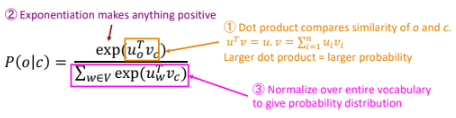 소프트맥스 함수 계산 과정
소프트맥스 함수 계산 과정
Optimization
Word2Vec은 경사 하강법 Gradient Descent 을 통해 목적 함수 $J(\theta)$를 최소화한다.
경사 하강법을 통해 주변 단어와 중심 단어 벡터에 대한 기울기를 갱신한다.
주변 단어 벡터 $u_o$에 대한 기울기 \(\frac{\partial J}{\partial u_o} = v_c - P(o \mid c)v_c\)
중심 단어 벡터 $v_c$에 대한 기울기 \(\frac{\partial J}{\partial v_c} = u_o - \sum_{w \in V} P(w \mid c) u_w\)
각 벡터 업데이트 \(v_c \leftarrow v_c - \eta \frac{\partial J}{\partial v_c}, \quad u_o \leftarrow u_o - \eta \frac{\partial J}{\partial u_o}\)
- $\eta$: 학습률 (Learning Rate)
그러나, 경사 하강법을 적용하면, 단어의 개수가 많을수록 소프트맥스 함수에 대한 계산량이 기하급수적으로 증가하며, 학습 속도가 매우 느려진다.
Word2Vec은 이러한 문제를 해결하기 위해 확률적 경사 하강법 Stochastic Gradient Descent 과 네거티브 샘플링 Negative Sampling 을 활용한다.
확률적 경사 하강법
확률적 경사 하강법 Stochastic Gradient Descent 은 전체 데이터셋 대신 작은 배치에 대해 기울기를 계산하고, 파라미터를 업데이트한다.
\[v_c \leftarrow v_c - \eta \frac{\partial J_{sample}}{\partial v_c}, \quad u_o \leftarrow u_o - \eta \frac{\partial J_{sample}}{\partial u_o}\]- $J_{sample}$: 단일 샘플(또는 미니배치)에 대한 손실 함수
- $\eta$: 학습률
네거티브 샘플링
네거티브 샘플링 Negative Sampling 은 전체 단어 집합 $V$를 고려하는 대신, 일부 네거티브 샘플 (부정 단어)만 선택해 학습하는 방법으로,
소프트맥스 대신 바이너리 로지스틱 회귀 문제로 변환하여 계산량을 줄인다. 2
\[J_{\text{neg}}(\theta) = - \log \sigma(u_o^\top v_c) - \sum_{i=1}^k \log \sigma(-u_{n_i}^\top v_c)\]- 첫 번째 항: 중심 단어 $c$와 실제 주변 단어 $o$의 관계를 강화
- 두 번째 항: 중심 단어 $c$와 네거티브 샘플 $n_i$의 관계를 약화
추가적으로, 단어 확률 계산을 트리 구조로 수행하는 Hierarchical Softmax, 자주 출현하는 단어에 대해 정보의 가치를 줄이는 Subsampling of Frequent Words 방법을 추가 고려하여 계산 효율성을 극대화할 수 있다.
Code
파이썬의 gensim 패키지를 통해 Word2Vec을 활용할 수 있다.
다음은 네이버 영화 리뷰 데이터를 통해 Word2Vec을 학습하는 코드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import pandas as pd
import matplotlib.pyplot as plt
import urllib.request
from konlpy.tag import Okt
from gensim.models import Word2Vec
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
train_data = pd.read_table('ratings.txt')
train_data = train_data.dropna(how = 'any') # Null 값이 존재하는 행 제거
print(train_data.isnull().values.any()) # Null 값이 존재하는지 확인
# 정규 표현식을 통한 한글 외 문자 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","", regex=True)
# 불용어 정의
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 형태소 분석기 OKT를 사용한 토큰화 작업 (다소 시간 소요)
okt = Okt()
tokenized_data = []
for sentence in tqdm(train_data['document']):
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)
model = Word2Vec(sentences = tokenized_data, vector_size = 100, window = 5, min_count = 5, workers = 4, sg = 0)
하지만, 사전에 이미 훈련된 워드 임베딩을 활용하는 것이 다양한 언어 작업에 있어 더욱 효과적이다.
다음은 구글에서 제공하는 사전 훈련된 Word2Vec 모델을 활용하는 코드이다.
1
2
3
4
5
6
7
import gensim
import urllib.request
# 구글의 사전 훈련된 Word2Vec 모델을 로드.
urllib.request.urlretrieve("https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz", \
filename="GoogleNews-vectors-negative300.bin.gz")
word2vec_model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz', binary=True)
결론
단어 의미를 표현하는 다양한 방법을 살펴보았다. 단순한 WordNet, One-hot Vectors를 시작으로 문맥을 반영하는 Distributional Semantic, 이를 반영한 Word Vectors 중 신경망 기반으로 학습하는 Word2Vec까지 발전하는 과정을 이해할 수 있었다.