[ML] Ensemble (앙상블) - [1] Ensemble, Combination Strategy: Voting, Averaging, Stacking

Ensemble Series
- [1] Ensemble, Combination Strategy: Voting, Averaging Stacking
- [2] Approach 1. Bagging - Random Forest
- [3] Approach 2. Boosting - AdaBoost, Gradient Boost
머신러닝 프로젝트를 진행하고 모델 간의 성능을 비교할 때, 앙상블 모델이 대부분 상위에 랭크되는 것을 자주 확인할 수 있다.
그렇다면 왜 앙상블 모델이 보편적으로 뛰어난 성능을 보일까?
앙상블 모델의 원리와 개별 모델의 결합 전략을 알아보자.
앙상블은 여러 모델을 결합하여 개별 모델의 약점을 보완하고 전체적인 예측 성능을 향상시킨다.
하지만, 여러 모델을 결합한다고 무조건 개별 모델보다 좋은 성능을 기록하는 것은 아니다.
앙상블 모델이 개별 모델보다 성능이 향상되기 위해 필요한 두 가지 특성
다양성과 정확성
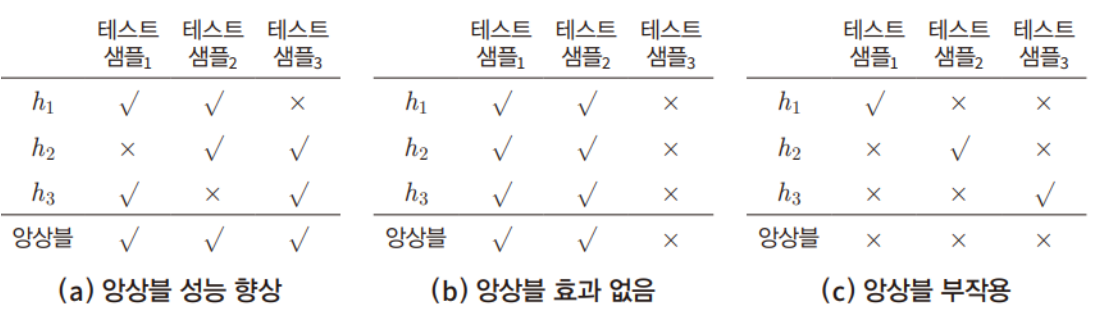 앙상블 학습 예시
앙상블 학습 예시
위의 예시는 3개의 개별 모델에 대한 테스트 샘플의 분류 결과이다.
| (a) 개별 모델간 다양성과 개별 모델의 정확성이 모두 충족 | 성능 향상 |
| (b) 다양성 충족 X | 성능 동일 |
| (c) 정확성 충족 X | 성능 하락 |
(b)에서의 개별 모델은 모든 샘플에서 같은 결과를 보여 모델 간 다양성이 충족되지 않아 앙상블의 효과를 거두지 못했다.
(c)에서는 개별 모델이 모두 낮은 정확성을 보이며 오히려 앙상블 모델에서 부작용이 발생했다.
Combination Strategy
그렇다면, 앙상블 모델은 개별 모델을 어떻게 취합해서 최종 결과를 도출할 까?
크게 3가지의 전략이 존재한다.
- Rule-based learning
- Classification : Voting 투표법
- Hard Voting 직접 투표, Soft Voting 간접 투표
- Regression : Averaging 평균법
- Classification : Voting 투표법
- Meta-learning
- Stacking
Voting
먼저, Voting은 분류 문제에서 활용된다.
| Hard Voting 직접 투표 | 가장 많은 표를 얻은 클래스가 앙상블의 최종 예측이 되는 방법이다. |
- i번째 분류기는 j 클래스에 대해 0 또는 1로 라벨링
- 최종 예측은 모든 분류기에서 가장 많은 표를 받은 클래스 j로 예측
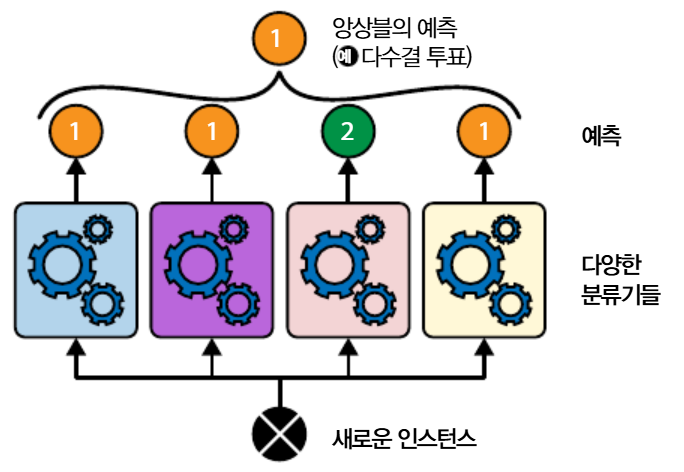 Hard Voting
Hard Voting
위는 가장 많은 표를 얻은 1번 클래스가 앙상블의 최종 예측 클래스가 된다.
| Soft Voting 간접 투표 | 각 개별 모델이 클래스의 확률을 예측할 수 있다면, 각 모델의 예측을 평균 내어 확률이 가장 높은 클래스를 예측한다. |
- i번째 분류기는 j 클래스에 대해 0에서 1 사이의 확률로 예측
- 최종 예측은 모든 분류기에서 가장 높은 확률을 부여받은 클래스 j로 예측
Code
Scikit-learn의 VotingClassifier를 통해 투표 기반 분류기를 생성하고 훈련할 수 있다.
로지스틱 회귀, 랜덤 포레스트, SVC 3가지의 개별 모델의 예측을 집계하여 최종 예측을 결정하며, voting 매개변수를 “soft”로 바꾸면 모든 개별 모델이 클래스의 확률을 추정할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# make_moons 함수를 사용하여 데이터셋 생성
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
# 생성한 데이터를 학습용 데이터와 테스트용 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 세 가지 분류 모델을 결합한 VotingClassifier 생성
voting_clf = VotingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)), # 로지스틱 회귀 모델
('rf', RandomForestClassifier(random_state=42)), # 랜덤 포레스트 모델
('svc', SVC(random_state=42)) # 서포트 벡터 머신 모델
])
# VotingClassifier를 학습용 데이터로 학습시킴
voting_clf.fit(X_train, y_train)
# 각 개별 분류 모델의 테스트셋 성능 출력
for name, clf in voting_clf.named_estimators_.items():
print(name, "=", clf.score(X_test, y_test))
# 투표 기반 분류기의 테스트셋 성능 출력
print(voting_clf.score(X_test, y_test))
# Soft Voting 사용
voting_clf.voting = "soft"
voting_clf.named_estimators["svc"].probability = True # SVC는 클래스 확률을 제공하지 않으므로 따로 지정 필요
voting_clf.fit(X_train, y_train)
print(voting_clf.score(X_test, y_test))
Averaging
Averaging은 회귀 문제에서 활용된다.
| Averaging 평균법 | 각 분류기의 수치형 값을 평균하여 최종 예측을 진행한다. |
Stacking
| Stacking | “예측을 취합하는 모델을 훈련시킬 수는 없을까?”라는 아이디어에 착안해 등장하였다. |
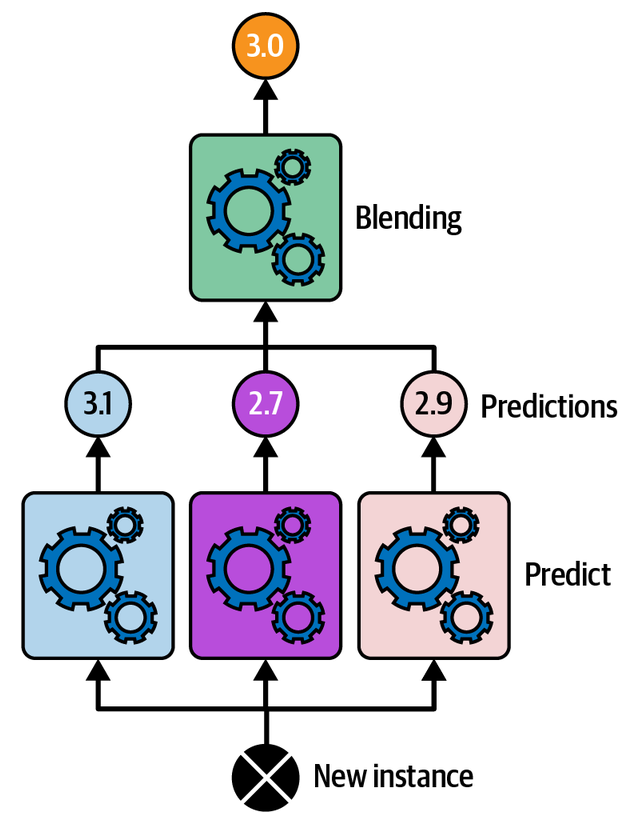 Stacking
Stacking
각 개별 학습기의 예측을 기반으로 최종 학습기 (Blender, Meta learner)가 예측을 수행한다.
이 때, 개별 학습기의 훈련 데이터로 최종 학습기의 훈련 데이터셋을 만들면 과적합의 우려가 있다. 대신, 교차 검증이나 홀드아웃을 사용해 개별 학습기 훈련에 사용되지 않은 샘플을 사용해야 한다.
Code
사이킷런의 StackingClassifier 또는 StackingRegressor를 통해 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.ensemble import StackingClassifier
stacking_clf = StackingClassifier(
estimators=[ # 개별 학습기
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(probability=True, random_state=42))
],
final_estimator=RandomForestClassifier(random_state=43), # 최종 학습기
cv=5 # 교차 검증 폴드 개수
)
stacking_clf.fit(X_train, y_train)
위 코드에서 최종 학습기인 final_estimator 값을 지정하지 않은 경우, 분류는 LogisticRegression, 회귀는 RidgeCV를 사용한다.