[ML] Linear Regression (선형 회귀) - [1] 수학적 증명과 이론
Math for ML Series
- [1] Linear Regression - 수학적 증명과 이론
- [2] Logistic Regression - 수학적 증명과 이론
- [3] Softmax Regression - 수학적 증명과 이론
- [4] Support Vector Machine - 수학적 증명과 이론
Linear Regression Series
- [1] Linear Regression - 수학적 증명과 이론
- [2] Linear Regression - 여러 구현 방법 및 해석
Linear Regression
선형 회귀 Linear Regression 은 머신러닝에서 가장 기본적이고 중요한 회귀 기법으로, 입력과 출력 사이의 선형 관계를 학습한다.
본 포스팅에서는 수학적 이론과 선형대수학을 통해 선형 회귀가 어떻게 동작하는 지 살펴본다.
훈련 함수
선형 회귀는 다음 문제를 해결한다.
데이터 간 관계 파악 독립 변수($x$)가 종속 변수($y$)에 어떤 영향을 미치는 지 설명한다. 미래 예측 주어진 데이터를 기반으로 새로운 입력에 대한 출력을 예측한다.
선형 회귀는 여러 독립 변수를 포함하며, 다음과 같은 훈련 함수를 가진다.
\[\hat{y} = \theta_0 + \theta_1x_1 + \theta_2x_2 + ⋯ + \theta_px_p\] \[\hat{y} = \sum_{j=0}^{p}\theta_jx_j\]- $x$: 독립 변수 Feature, Independent Variable
- $\hat{y}$: 예측 변수 Prediction
- $\theta$: 파라미터 Weight, Parameter
하나의 데이터 포인트에 대해 생각했을 때, 두 벡터의 내적을 활용하여 다음과 같이 정의할 수 있다.
\[\hat{y} = x^T\theta\] \[\hat{y} = \begin{bmatrix} 1 & x_1 & ... & x_p \end{bmatrix} \begin{bmatrix} \theta_0 \\ \theta_1 \\ ... \\ \theta_p \end{bmatrix}\]- $x \in \mathbb{R}^{(p+1) \times 1}, \quad \theta \in \mathbb{R}^{(p+1) \times 1}$
이를 모든 데이터에 확장하여 선형대수학에 의해 일반화하면:
\[\hat{y} = X\theta\] \[\begin{bmatrix} \hat{y}_1 \\ \hat{y}_2 \\ ... \\ \hat{y}_n \end{bmatrix} = \begin{bmatrix} 1 & x_{11} & ... & x_{1p} \\ 1 & x_{21} & ... & x_{2p} \\ 1 & ... & ... & ... \\ 1 & x_{n1} & ... & x_{np} \\ \end{bmatrix} \begin{bmatrix} \theta_0 \\ \theta_1 \\ ... \\ \theta_p \end{bmatrix}\]- $X: n \times (p + 1)$ 크기의 행렬 ($n$ : 샘플 수, $p$ : 차원 수)
- $\hat{y}: n \times 1$ 크기의 벡터
손실 함수
선형 회귀는 예측값 $\hat{y}$와 실제값 $y$ 간의 차이를 최소화한다. 차이를 측정하기 위해 손실 함수를 사용하며, 다음 두 방식을 고려할 수 있다.
\[R(\theta) = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y_i})^2\]L2 Loss (MSE): 제곱 거리
\[R(\theta) = \frac{1}{n}\sum_{i=1}^{n}\left|y_i - \hat{y_i} \right|\]L1 Loss (MAE): 절댓값 거리
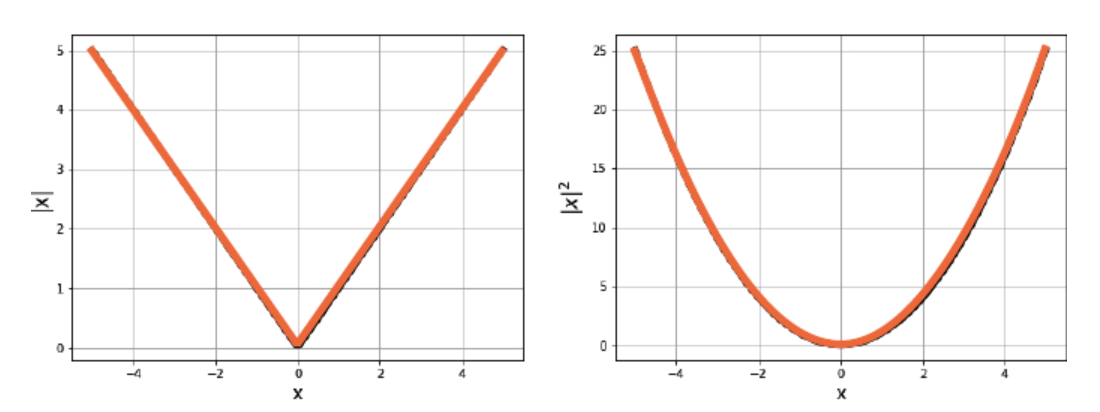 L1 Loss, L2 Loss
L1 Loss, L2 Loss
L1 Loss는 이상치에 강건하지만, 미분이 불가능한 지점이 존재하여 불안정하다.
L1 Loss는 신경망 훈련 함수 (ReLU), 정규화 항 (Lasso 회귀) 등에서 활용된다.
반면, L2 Loss는 손실 함수의 곡선이 매끄럽고 최적화가 상대적으로 수월하므로, 선형 회귀의 손실 함수로는 일반적으로 L2 Loss가 활용된다.
OLS
Ordinary Least Squares (OLS)는 L2 Loss를 최소화하는 예측값 $\hat{y}$가 실제값 $y$와 가장 가깝도록 하는 선형 회귀 방법으로,
다음과 같은 행렬 표현으로 나타낼 수 있다.
\[Minimize: R(\theta) = \frac{1}{n}\left\| y - X\theta \right\|_2^2\]최적화
정의한 손실 함수 $R(\theta)$를 최소화하는 파라미터 $\hat{\theta}$를 찾아야 한다.
최적화 문제는 미적분, 선형대수학, 두 가지 관점에서 해결할 수 있다.
미적분 관점
손실 함수의 도함수를 계산하여 기울기가 0인 지점을 찾는다.
손실 함수 미분
$R(\theta)$를 $\theta$에 대해 미분하여, 기울기가 0이 되는 지점을 찾는다.
\[\frac{\partial R(\theta)}{\partial \theta} = -\frac{2}{n} X^T (y - X\theta)\]최적 조건 설정
미분값이 0이 되는 최적 조건을 도출한다.
\[X^T X\theta = X^T y\]파라미터 계산
위의 정규 방정식을 풀어 최적의 $\theta$를 계산한다.
\[\theta = (X^T X)^{-1} X^T y\]
선형대수학 관점
잔차 벡터 $r$이 행렬 $X$의 열 벡터들이 생성하는 공간 $\text{span}(X)$에 직교 Orthogonal하도록 설정한다.
손실 함수 재해석
잔차 벡터 $r = y - \hat{y}$의 크기를 최소화하는 $\theta$를 찾아야 한다.
\[\min_\theta \|y - X\theta\|_2^2\]직교 투영의 성질
$\hat{y} = X\theta$는 $y$를 $\text{span}(X)$에 직교 투영(orthogonal projection)한 결과이며, 잔차 벡터 $r$는 $\text{span}(X)$와 직교한다.
Orthogonality:
- 벡터 $a$와 $b$가 orthogonal하면, $a^Tb = 0$을 만족한다.
- 벡터 $v$가 $\text{span}(M)$에 orthogonal하면, $v$는 행렬 $M$의 모든 열 벡터 $m_j$에 대해 $v^T m_j = 0$을 만족한다. 이는 $v$와 $\text{span}(M)$ 간의 직교성을 의미한다.
위의 성질에 따라, $r = y - \hat{y}$는 $\text{span}(X)$에 직교한다.
\[X^T(y - X\theta) = 0\]정규 방정식 도출 및 파라미터 계산
이후 과정은 동일하다.
\[X^T X\theta = X^T y\] \[\theta = (X^T X)^{-1} X^T y\]
결론
이번 포스팅에서는 선형 회귀의 최적화 문제를 미적분, 선형대수학 두 관점에서 살펴보았다. 이를 통해, 선형 회귀 모델이 데이터를 가장 잘 설명하는 파라미터를 찾는 과정을 수학적으로 이해할 수 있다.
다음 포스팅에서는 파이썬을 활용한 선형 회귀 구현 방법에 대해 설명하고자 한다.