[Causal Inference] 실무로 통하는 인과추론 - [1] 인과추론 기초와 중요성
Casual Inference Series
- [1] 인과추론 기초와 중요성
- [2] 무작위 통제 실험
- [3] 그래프 인과모델
- [4] 편향 점수
이번 글에서는 인과추론의 기본 개념, 필요성, 실무적 적용 사례를 바탕으로 데이터 기반 의사결정에서 인과추론이 왜 중요한지 살펴본다.
인과추론의 개념 및 목적
인과추론 Causal Inference 은 상관관계로부터 인과관계를 추론하는 과학적 방법론이다.
“서로 어떻게 관련이 있는가?”를 넘어, “무엇이 무엇을 원인으로 만들어내는가?를 이해하는 데 초점을 맞춘다.
많은 데이터 과학자들은 변수 간 상관관계를 이용해 다른 변수를 예측하는 머신러닝에 더 초점이 맞춰져 있지만, 사실 상관관계보다 인과관계를 파악하는 것이 더 중요한 경우가 많다.
원인과 결과의 관계를 알아야만 원인에 개입하여 원하는 결과를 가져올 수 있기 때문이다.
실무자들이 상관관계가 아닌 인과관계에 주목하는 이유는 다음과 같다.
- Action: 지표 간 상관관계만으로 실무자가 문제 해결에 대한 행동 Action 을 취할 수 없음
- Decision: 상관관계는 중요하지만, 의사결정 Decision 에 활용할 수 없음
- Growth: 인과관계를 파악해야, 유저 경험 개선 및 제품 성장 Growth 에 기여할 수 있음
최종적으로, 인과추론을 통해 현실의 문제를 이해하고 개인 및 조직 차원에서 문제 해결을 통해 성장을 도모할 수 있다.
실무적 차원에서는 구성원들이 더 나은 의사결정을 할 수 있도록 돕고, 사용자 경험을 개선할 수 있다.
인과추론 활용 사례
1) 가격 할인과 매출 증진
- 가설: 가격 할인 -> 매출 증진
- 문제: 회사 규모와 같은 교란 요인이 결과에 영향을 줄 수 있다.
- 해결책:
- 무작위 처치 RCT: 가격 할인을 랜덤하게 배정
- 조건부 분석 Conditioning: 교란 요인을 통제 변수로 포함해 특정 규모의 회사 대상으로 분석
2) 스토어 광고와 전환율 증대
- 가설: 스토어 광고 -> 전환율 증대
- 스토어 광고 방법: ASO 최적화 / 마켓 피쳐드 / 인기차트 / 인스톨 캠페인
- 해결책: A/B 테스트
인과추론 기본 용어
- 처치 treatment $T$ : 구하려는 효과에 대한 개입
- $T = 1$: 처치가 이루어진 상태, $T = 0$: 처치가 이루어지지 않은 상태
- ex) 가격 할인 여부
- 결과 outcome $Y$ : 처치가 미치는 결과로, 영향을 주려는 변수
- ex) 주간 판매량
- 개입 intervention $\text{do}(.)$ : 인과모델을 개선하여 인과적 질문의 답을 구하는 과정
- $\text{do}(T = t_0)$: 처치 $T$에 개입
- 잠재적 결과 potential outcome $Y_i$ : 처치 여부에 따른 두 결과
- $Y_i$: 처치가 $t$인 상태일 때, 실험 대상 $i$의 결과는 $Y$가 될 것이다. \(Y_i = T_iY_{1i} + (1-T_i)Y_{0i}\)
- 사실적 결과 factual outcome $Y_{1i}$ : 관측할 수 있는 한 가지 결과
- $Y_{1i}$: 처치받는 실험 대상 $i$의 잠재적 결과
- 반사실적 결과 counterfactual outcome $Y_{0i}$ : 관측할 수 없는 다른 한 가지 결과
- $Y_{0i}$: 처치받지 않은 실험 대상 $i$의 잠재적 결과
개별 처치효과 individual treatment effect (ITE) $\tau_i$ : 개별 실험 대상에 처치가 결과에 미치는 영향 \(\tau_i = Y_i \mid \text{do}(T = t_1) - Y_i \mid \text{do}(T = t_0)\)
- 편향 bias : 인과관계와 상관관계를 다르게 만드는 요소
인과추론의 근본적 문제
인과추론을 통한 질문은 대부분 “만약” What if? 으로 이루어진다.
- 현재 상품의 권장 가격 대신 다른 가격을 적용하면 어떻게 될까요?
- 고객의 신용 한도를 늘리면 은행의 이익은 어떻게 될까요?
- 읽기 시험 점수를 높이려면 정부가 모든 학생에게 태블릿을 지급해야 할까요? 도서관을 지어야 할까요?
그러나, 인과추론의 근본적 문제로, 동일한 실험 대상이 처치를 받은 상태와 받지 않은 상태를 동시에 관측할 수 없다는 문제가 발생한다.
앞선 예시에서, 동일 회사가 할인했을 때의 판매량 $Y_1$과 할인하지 않았을 때의 판매량 $Y_0$을 동시에 관측할 수 없다.
즉, 다음과 같은 결측치 문제가 발생한다.
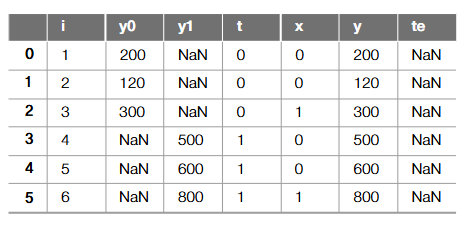 결측치 문제
결측치 문제
필연적으로 y0과 y1 중 한 값은 결측치가 발생하게 된다.
그렇다면, 어떻게 이를 해결할 수 있을까?
인과효과 식별
구하고 싶지만 관측할 수 없는 인과 추정량 Causal Estimand 은 식별 Identification 과정을 통해 데이터로 구할 수 있는 통계 추정량 Statistical Estimand 으로 해결한다.
이 때 중요한 것은, 실험군의 반사실이 대조군과 최대한 비슷하도록 설계해야 한다.
식별 과정에서는 일반적으로 두 가정이 동반되어야 한다.
- 무작위 처치 배정
- 독립성: 실험군과 대조군은 비교 가능
- SUTVA 가정 만족
- 상호 간섭 없음: 여러 형태의 처치는 없음
- 일치성: 다른 실험 대상의 영향을 받지 않음
위 2가지의 가정이 만족했을 때, 인과효과를 식별하고 추정할 수 있게 된다.
\[E[Y \mid T = 1] - E[Y \mid T = 0] = E[Y_1 - Y_0]\]인과 추정량
인과효과를 식별할 수 있는 3가지 인과 추정량이 존재한다.
- 평균 처치효과 Average Treatment Effect (ATE)
- 처치 $T$가 여러 실험 대상에 걸쳐 평균적으로 미치는 영향을 나타낸다.
- 실험군에 대한 평균 처치효과 Average Treatment effect on the Treated (ATT)
- ATT는 처치 받은 대상에 대한 처치효과를 나타낸다.
- 조건부 평균 처치효과 Conditional Average Treatment Effect (CATE)
- CATE는 변수 X로 정의된 그룹에서의 처치효과를 나타낸다.