[ML] Ensemble (앙상블) - [2] Approach 1. Bagging - Random Forest

Ensemble Series
- [1] Ensemble, Combination Strategy: Voting, Averaging, Stacking
- [2] Approach 1. Bagging - Random Forest
- [3] Approach 2. Boosting - AdaBoost, Gradient Boost
다음은 앙상블 학습의 접근법으로, 크게 두 가지의 방식이 존재한다.
- Bagging : 개별 학습기 간 의존성이 약하며, 동시에 생성하는 병렬화 방식 (ex. Random Forest)
- Boosting : 개별 학습기 간 의존성이 강하며, 순차적으로 생성하는 연속화 방식 (ex. XGBoost, LightGBM)
본 포스팅에서는 Bagging과 가장 대표적인 배깅 방법론인 Random Forest를 설명한다.
Bagging
Bagging 배깅은 Bootstrap Aggregating의 줄임말로, 훈련 데이터에서 반복적으로 복원 랜덤 샘플링(Bootstrap)하고 각 샘플 데이터에서 모델을 학습해 결과를 집계(Aggregate)하는 방법이다.
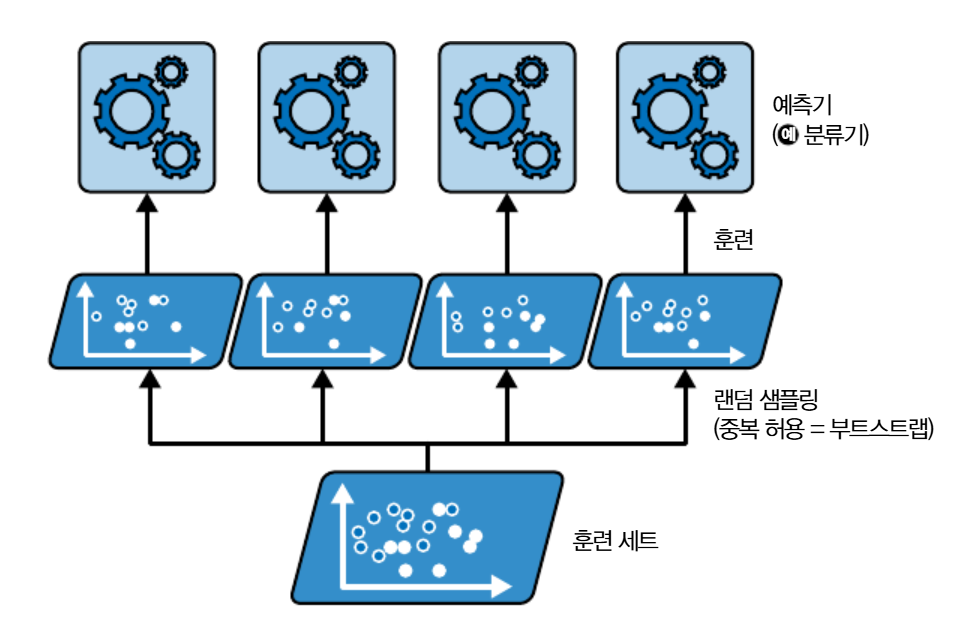 bagging
bagging
복원 랜덤 샘플링을 통해 데이터를 선택할 경우, 어떤 샘플은 여러 번 추출되는 반면, 어떤 것은 추출되지 않을 수 있다.
평균적으로 각 분류기에 훈련 샘플의 63.2%가 추출되며, 추출되지 않은 36.8% 샘플은 OOB(Out-of-bag) 샘플로, 검증 세트로 활용된다.
왜 63.2%인가?
m개의 샘플에서 랜덤으로 하나를 추출할 때, 선택되지 않을 확률은 \((1 - \frac{1}{m})\)이고, m번 반복하면 선택되지 않을 확률은 \((1 - \frac{1}{m})^m\)이 된다. m을 무한대로 늘리면, 이 값은 로피탈의 정리에 의해 \((e^{-1} = 0.3679)\)와 같아지게 된다. 따라서, 샘플이 선택될 확률은 \(1 - 0.3679 = 0.6321\)로 약 63.2%이다.
Bootstrap 이후, Aggregation은 1편에서 언급한 방법을 활용하게 된다.
분류일 경우, Voting 회귀일 경우, Averaging 또는, 모델을 활용할 경우, Stacking
반면, 복원 추출하지 않고 비복원 랜덤 샘플링하는 Pasting 페이스팅 방식도 존재하는데, 이 경우 모든 샘플을 고르게 사용할 수 있고, 개별 모델 간의 다양성이 증가되는 효과가 발생한다. 그러나, 배깅보다 과적합 위험성이 크고, 분산 감소 효과는 제한적이다.
장점
| 분산 감소 | 샘플 변화에 민감한 학습기에 좋은 성능을 발휘한다. |
| 병렬 수행 가능 | 분산적으로 학습 및 예측이 가능하고 확장성이 높다. |
Code
Scikit-learn의 BaggingClassifier와 BaggingRegressor를 통해 배깅과 페이스팅을 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(),
bootstrap=True, # 배깅 : True(default), 페이스팅 : False
n_estimators=500, # 개별 의사결정나무 모델 500개 중에 (default : 10)
max_samples=100, # 랜덤 복원 방식으로 100개 추출 (default : 1)
n_jobs=-1, # 훈련과 예측에 사용할 CPU 코어 수 (-1은 모든 코어 사용, default : 1)
oob_score=True, # 훈련 종료 후 자동으로 OOB 평가 수행
random_state=42)
# 배깅 분류기 학습
bag_clf.fit(X_train, y_train)
# OOB 평가 정확도
print(bag_clf.oob_score_)
위 코드를 통해 배깅 분류기를 학습시킬 수 있고 OOB 평가도 가능하다.
Random Forest
Random Forest 랜덤 포레스트는 배깅 방법을 적용한 앙상블 모델로, 다음의 2가지 특징을 가진다.
랜덤 속성 선택 방식과 개별 의사결정나무 활용
랜덤 속성 선택은 전체 d개의 속성 집합 중 랜덤으로 k개의 속성 부분집합을 선택하여 그 중 하나의 최적 속성으로 노드를 분할하는 방식이다.
일반적으로 k는 \(log_2(d)\)를 사용한다.
즉, 전체 특성 d 중 \(log_2(d)\)만 사용하겠다는 말이다.
일반적인 배깅 방식은 부트스트랩을 통해 훈련 샘플을 샘플링한다. 랜덤 포레스트는 훈련 샘플과 특성을 모두 샘플링하는 랜덤 패치 방식이다.
랜덤 속성 선택은 더 다양한 예측기를 만들며, 편향을 늘리는 대신 분산을 감소시킨다.
Code
랜덤 포레스트는 Scikit-learn의 RandomForestClassifier 클래스를 활용해 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
iris = load_iris(as_frame=True)
rnd_clf = RandomForestClassifier(
n_estimators=500, # 500개의 개별 의사결정나무 활용
max_leaf_nodes=10, # 최대 리프 노드는 10개로 설정
n_jobs=-1,
random_state=42)
# BaggingClassifier 내 매개변수로 DecisionTreeClassifier 클래스를 선언해 동일하게 활용 가능
# rnd_clf = BaggingClassifier(
# DecisionTreeClassifier(
# max_features="sqrt",
# max_leaf_nodes=10),
# n_estimators=500, n_jobs=-1, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
# 특성 중요도 출력
for score, name in zip(rnd_clf.feature_importances_, iris.data.columns):
print(round(score, 2), name)
랜덤 포레스트는 특성 중요도를 측정할 수 있다. 특성 중요도는 평균적으로 불순도를 얼마나 감소시키는 지를 파악하여 측정된다.